Blackwell 可說是 NVIDIA 近年來幅度最大的 GPU 架構改動,劃時代導入神經網路著色器,為遊戲開創先進、高速且更擬真的渲染方式。
Blackwell 架構設計重點著重在為全新神經網路運算最佳化、降低記憶體耗用量、導入新式服務品質功能,以及提高能源使用效率等 4 個方向。
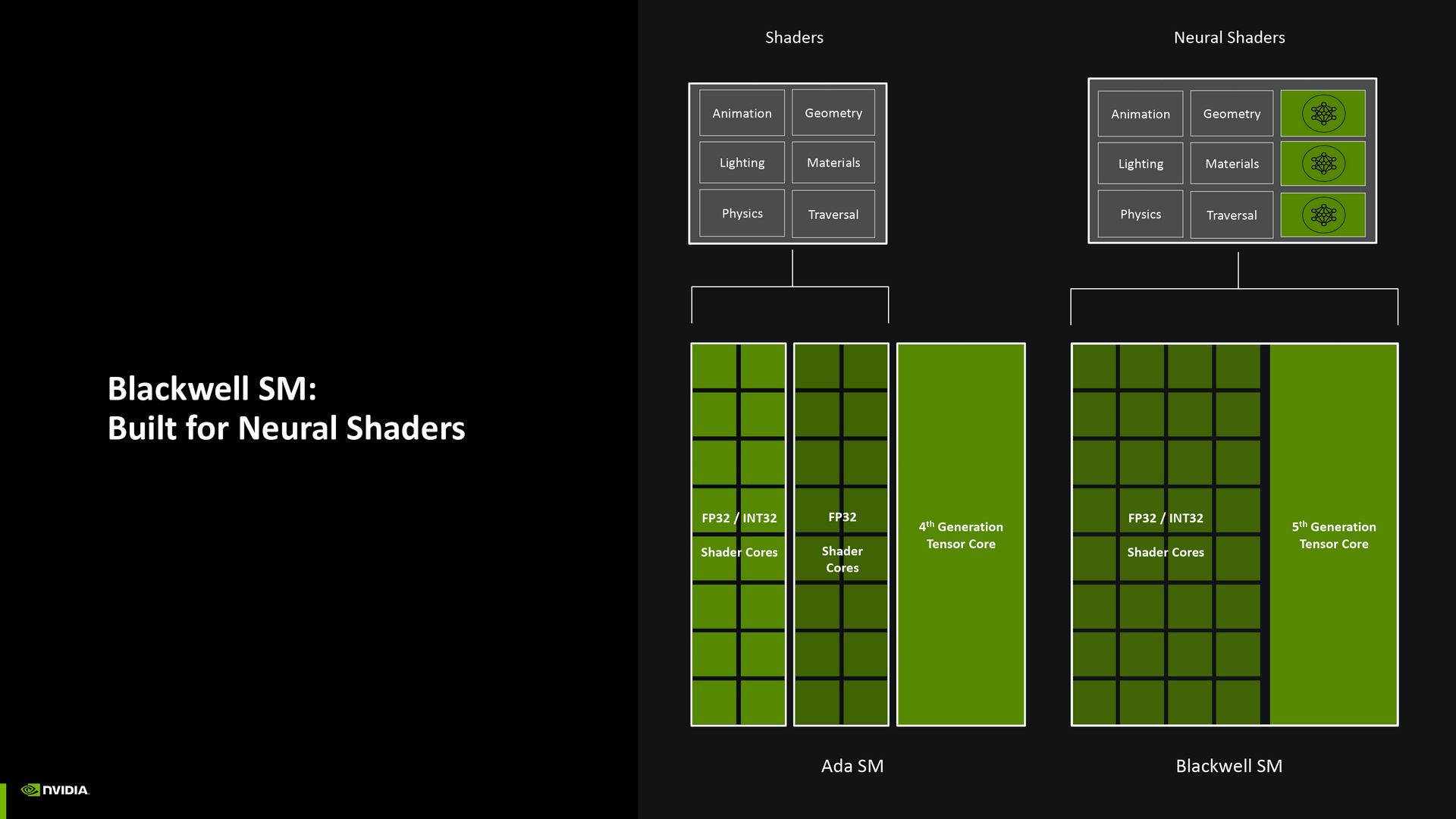
先從核心來看,相較於 Ada 架構 SM(Streaming Multiprocessor)內的著色核心(也就是 CUDA 核心)拆分成一半依需求動態調整處理 FP32(單精度浮點數)和 INT32(32 位整數),以及一半專門處理 FP32,Blackwell SM 的著色核心改成完全依需求動態處理 FP32 和 INT32。
同時,過往著色工作負載只由這些著色核心處理的情境,現在改成透過神經網路著色方式,納入 Blackwell 架構所擁有的第 5 代 Tensor 核心,共同分擔著色工作負載。
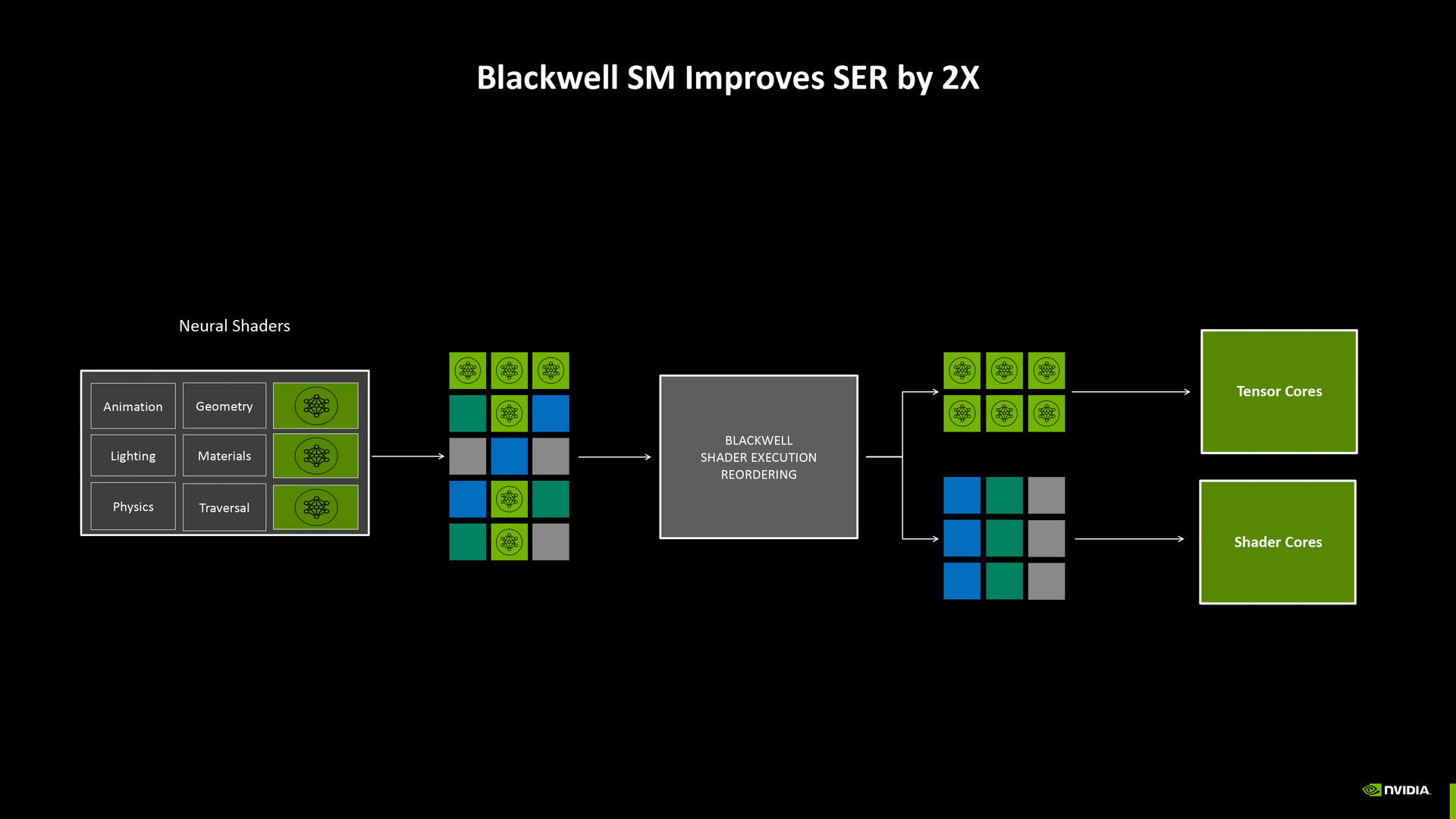
還有,相較於 Ada 架構的著色器執行重新排序(Shader Excution Reordering, SER)著重在光線追蹤工作負載的重新排序,Blackwell 架構進一步針對神經網路著色工作負載排序,把較傳統的著色工作分配給 CUDA 核心,需要動用神經網路運算的工作負載安排給 Tensor 核心,且兩種核心可以同時運用,讓整體效率提升至 2 倍。
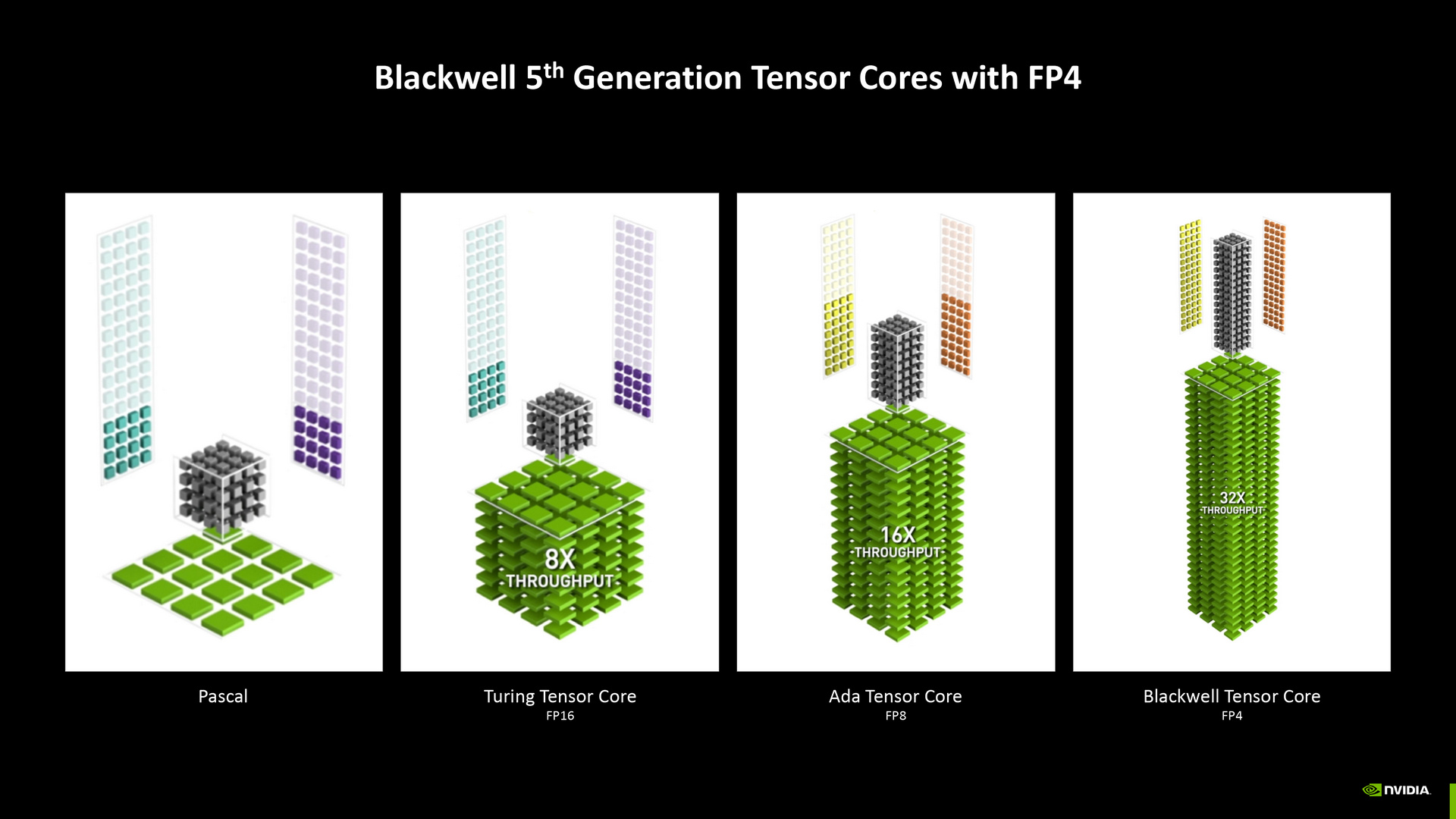
第 5 代 Tensor 核心支援 FP4 精度模型的加速處理,相較於 Ada 架構第 4 代 Tensor 核心支援的 FP8 精度模型,資料吞吐量可達 2 倍,相當於 Pascal 核心吞吐量的 32 倍,因此可滿足 DLSS 4 的多畫格生成技術。
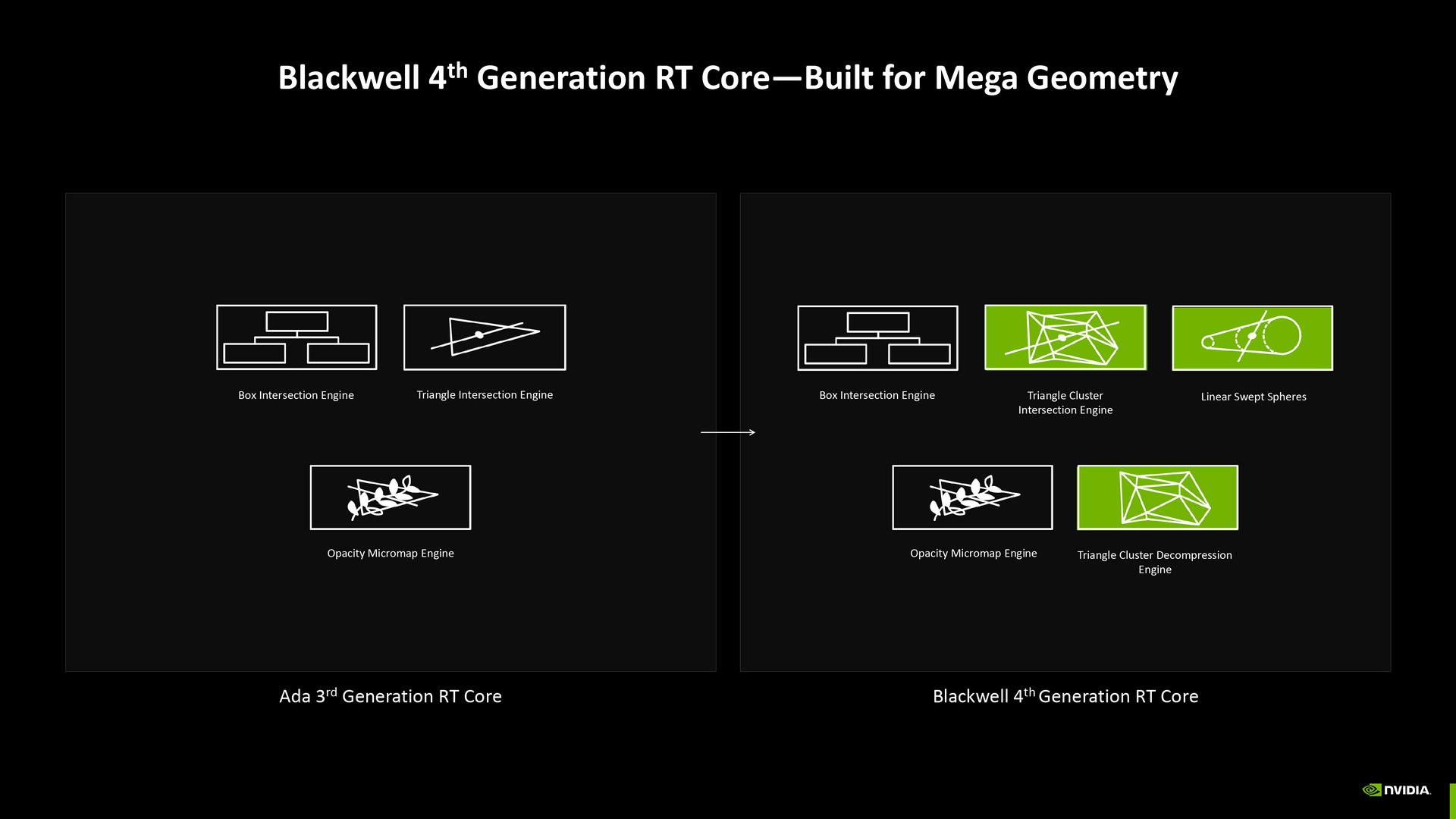
此外,相較於 Ada 架構的第 3 代光線追蹤核心,Blackwell 架構的第 4 代光線追蹤核心維持 Box Intersection Engine、Opacity Micromap Engine,把 Triangle Intersection Engine 拓展成 Triangle Cluster Intersection Engine,再加入 Triangle Cluster Decompression Engine 和 Linear Swept Spheres。
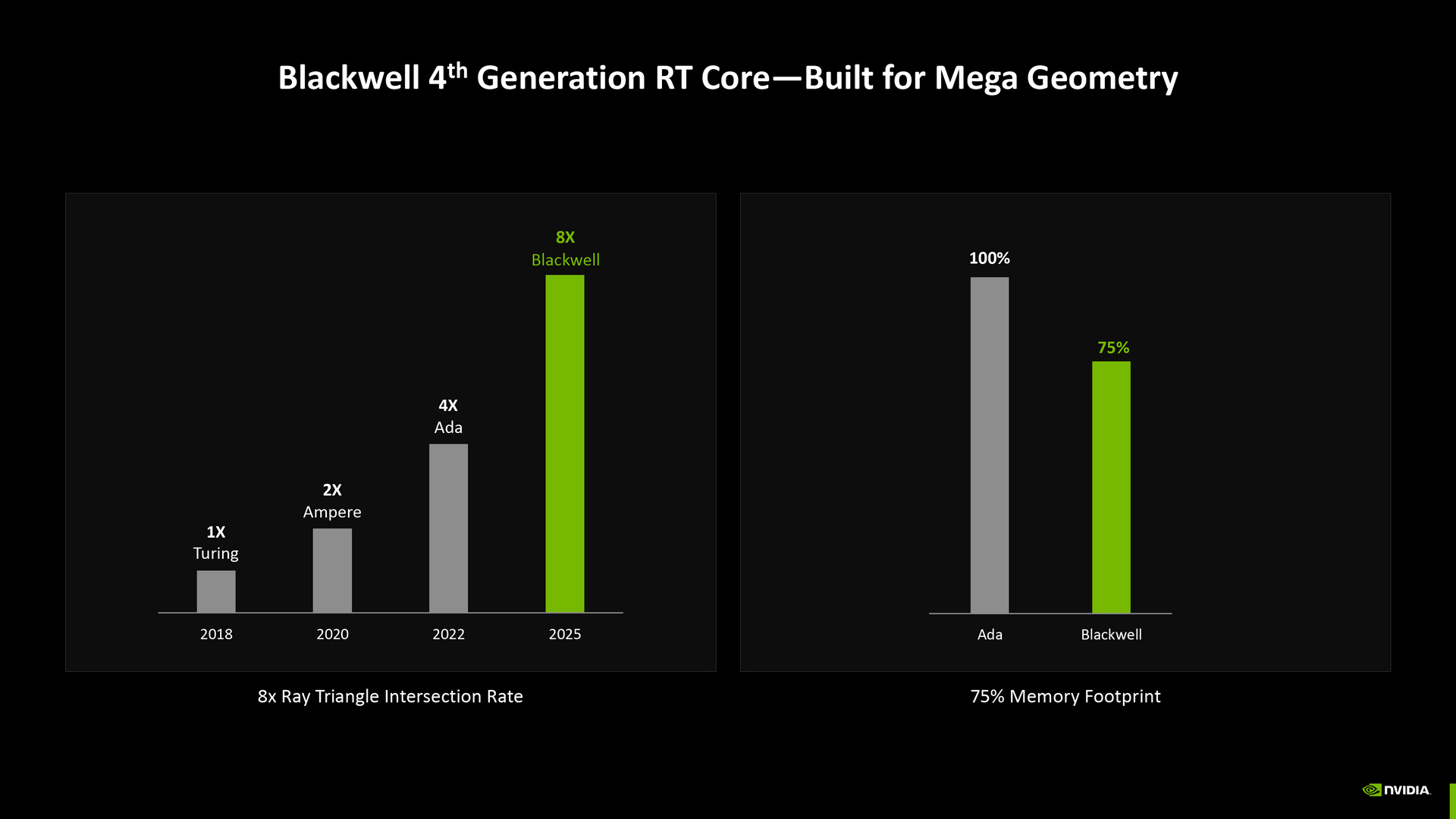
綜合來看,Blackwell 架構光線追蹤的多邊形交互率可達 Ada 架構的 2 倍,但記憶體耗用量只需要 Ada 架構的 75%。
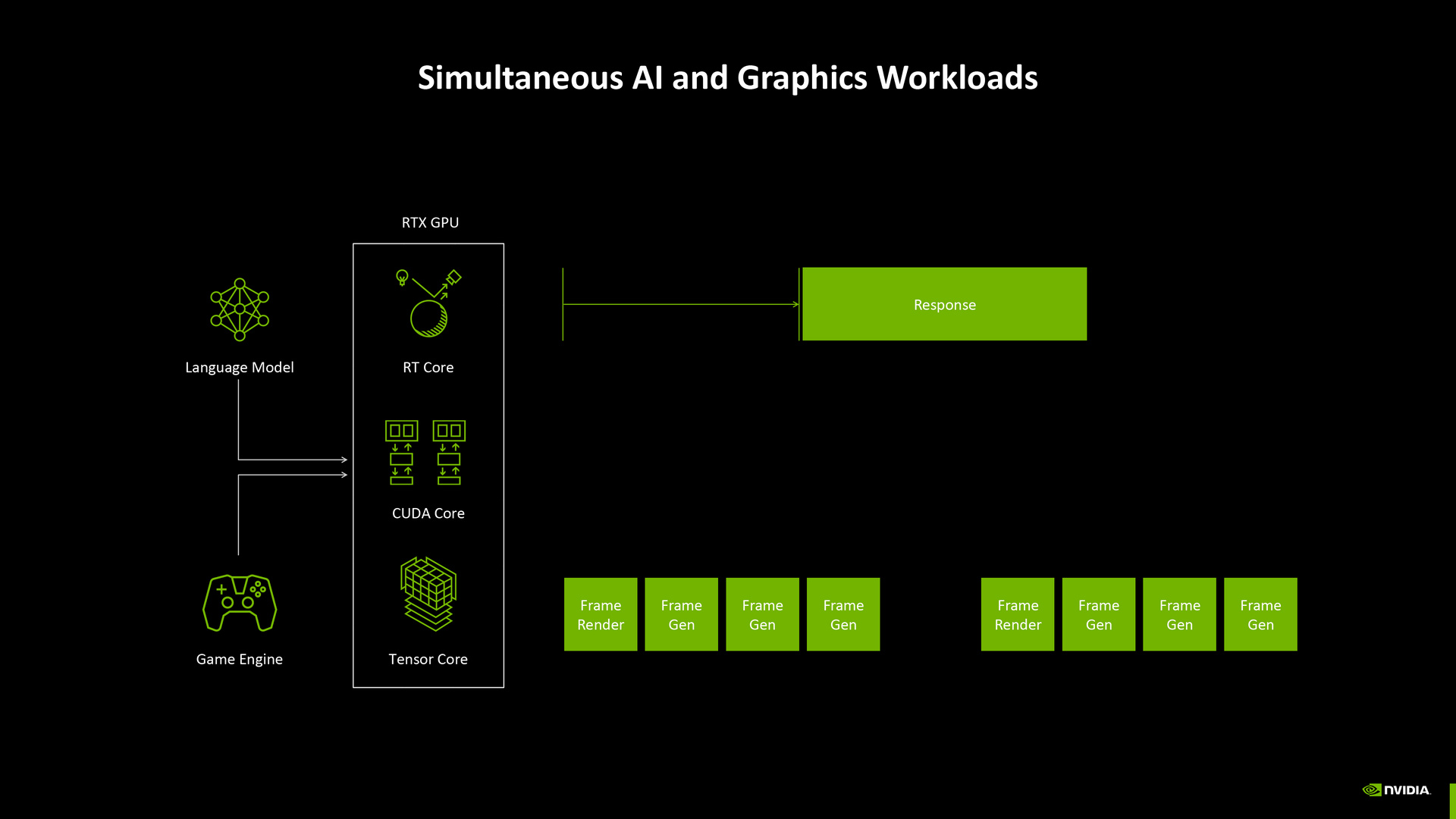
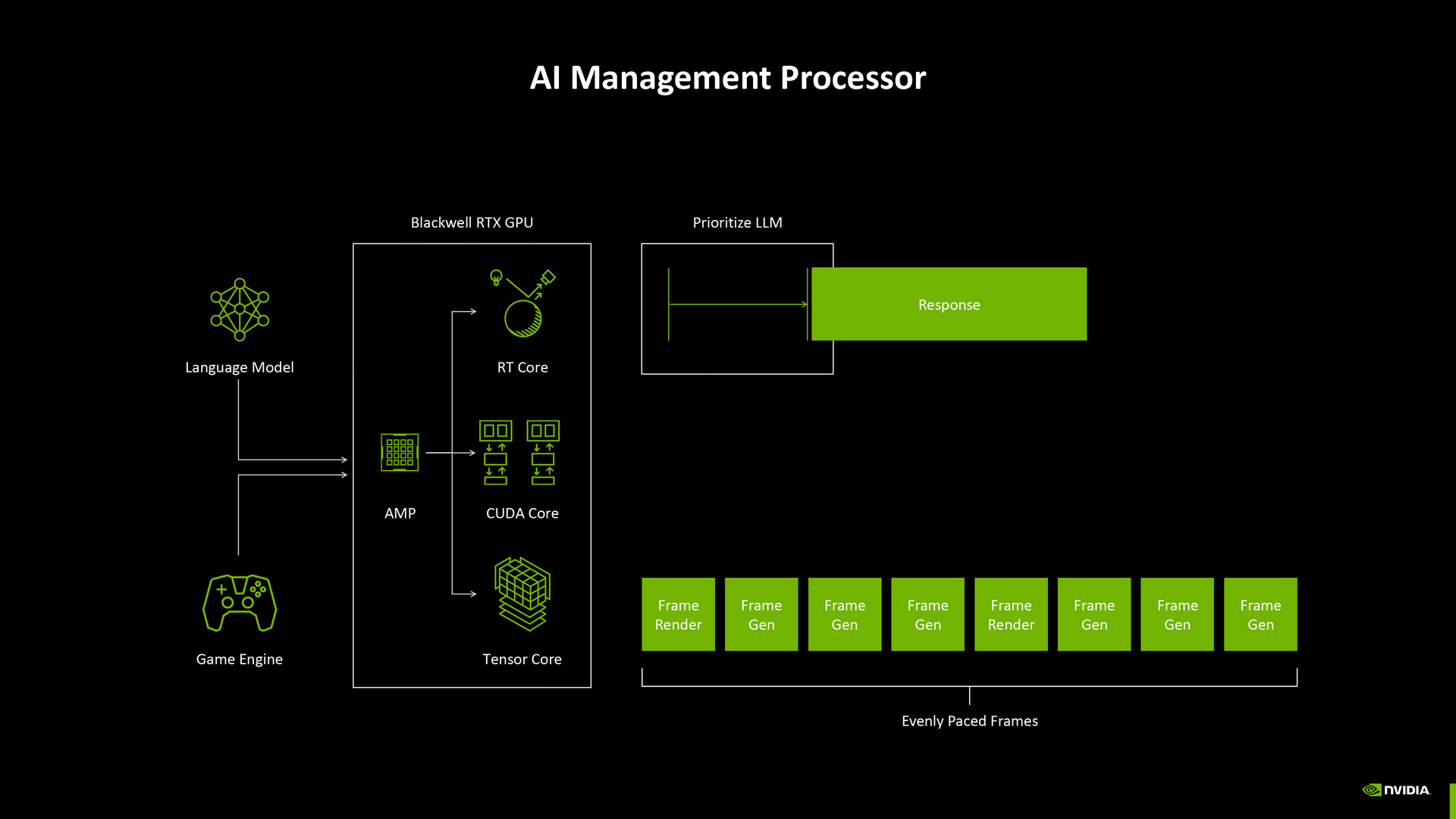
透過更先進的資源排程調度,Blackwell 架構能夠讓內部多種核心同步處理著色、光線追蹤與 AI 運算等負載,大幅縮短渲染的回應時間,進而提高整體效能。
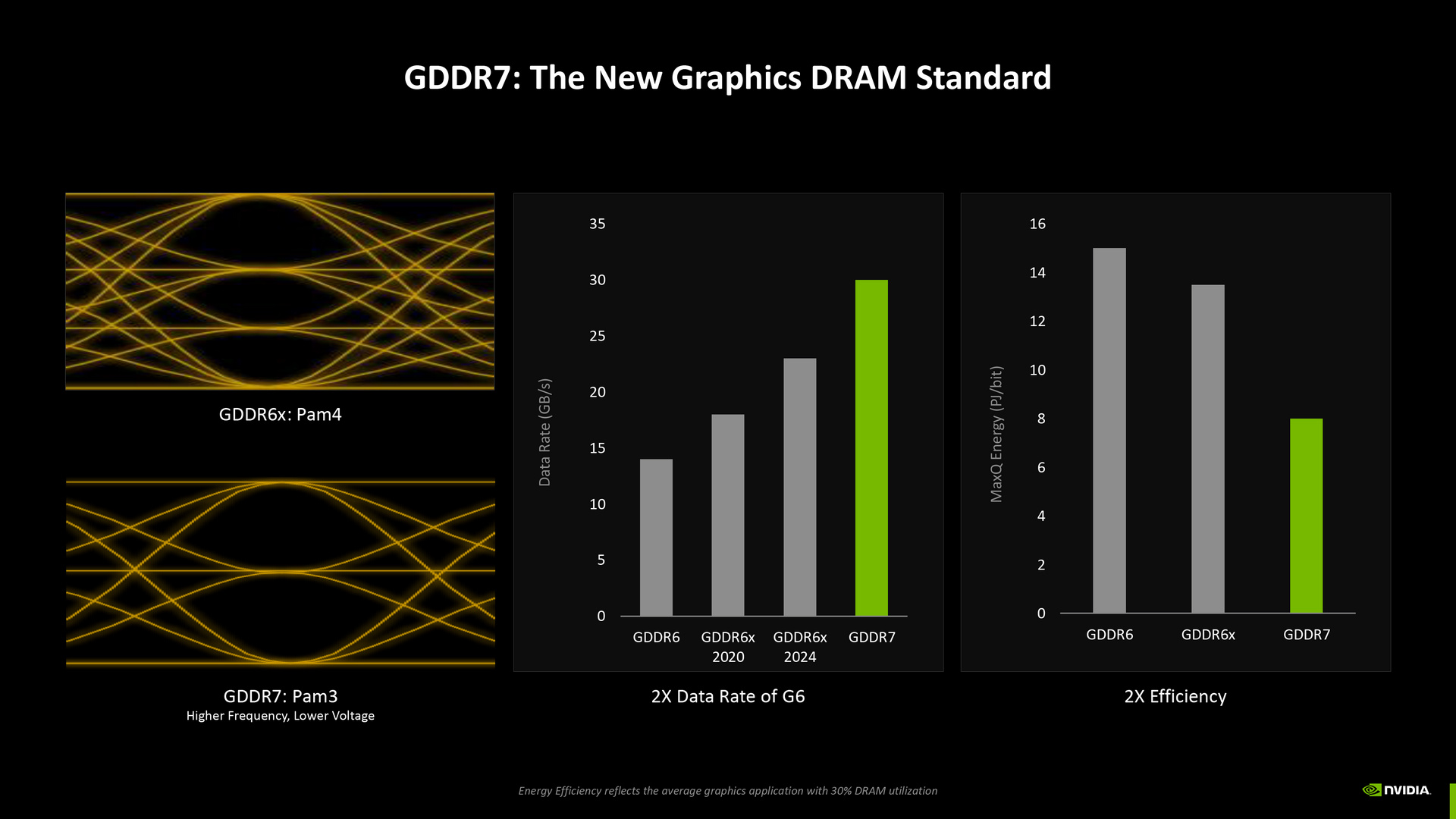
記憶體方面,前兩代 Ampere 和 Ada GPU 使用的 GDDR6X 記憶體訊號採 PAM4 編碼,Blackwell GPU 搭配的 GDDR7 記憶體訊號編碼改成 PAM3,雜訊失真比較小,訊號品質更清晰,藉此帶來更高的運作頻率與更低的電壓,資料速率可達 GDDR6 的 2 倍,每位元功耗接近 GDDR6 的一半,能源效率像當漁 2 倍。

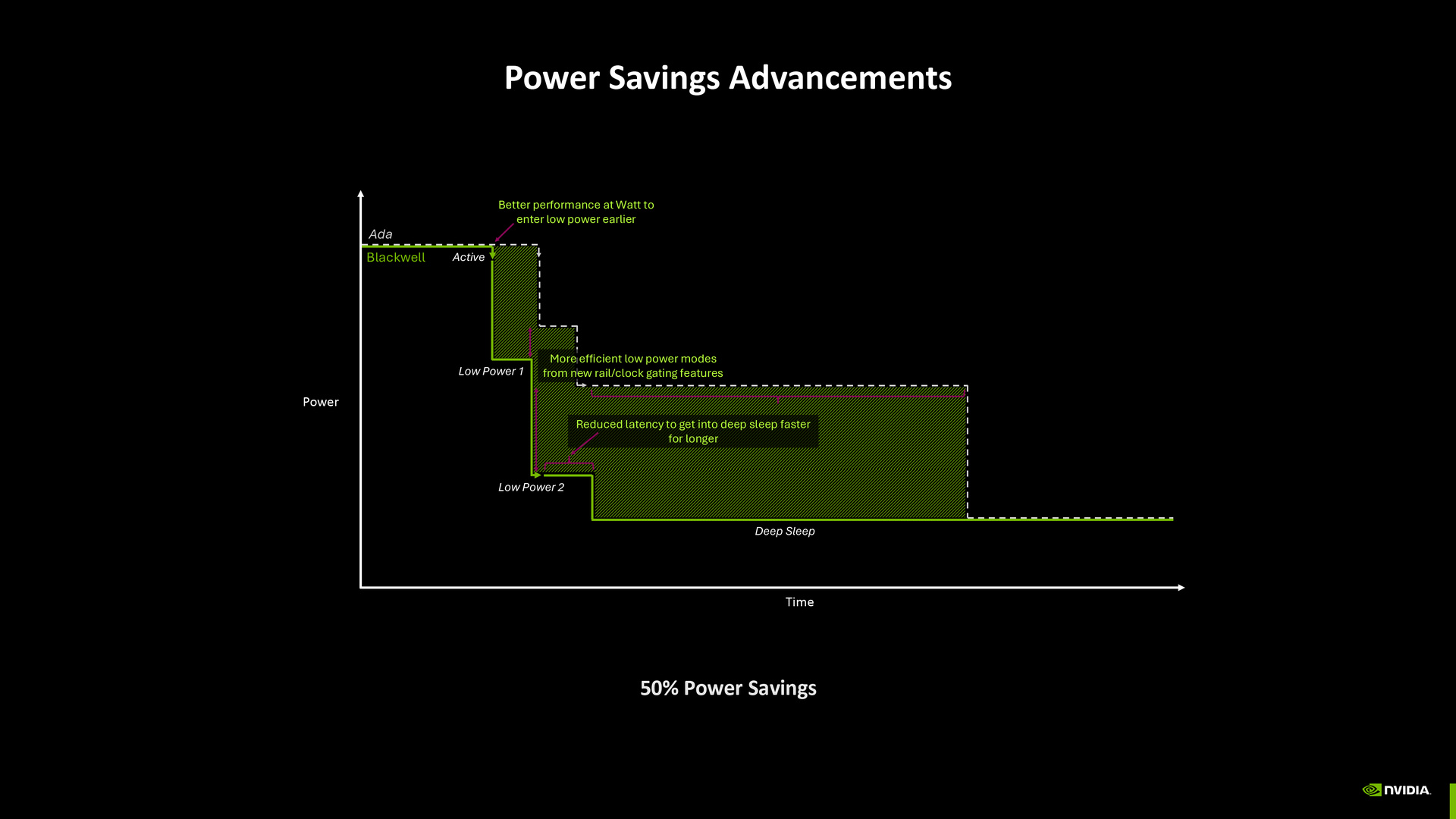
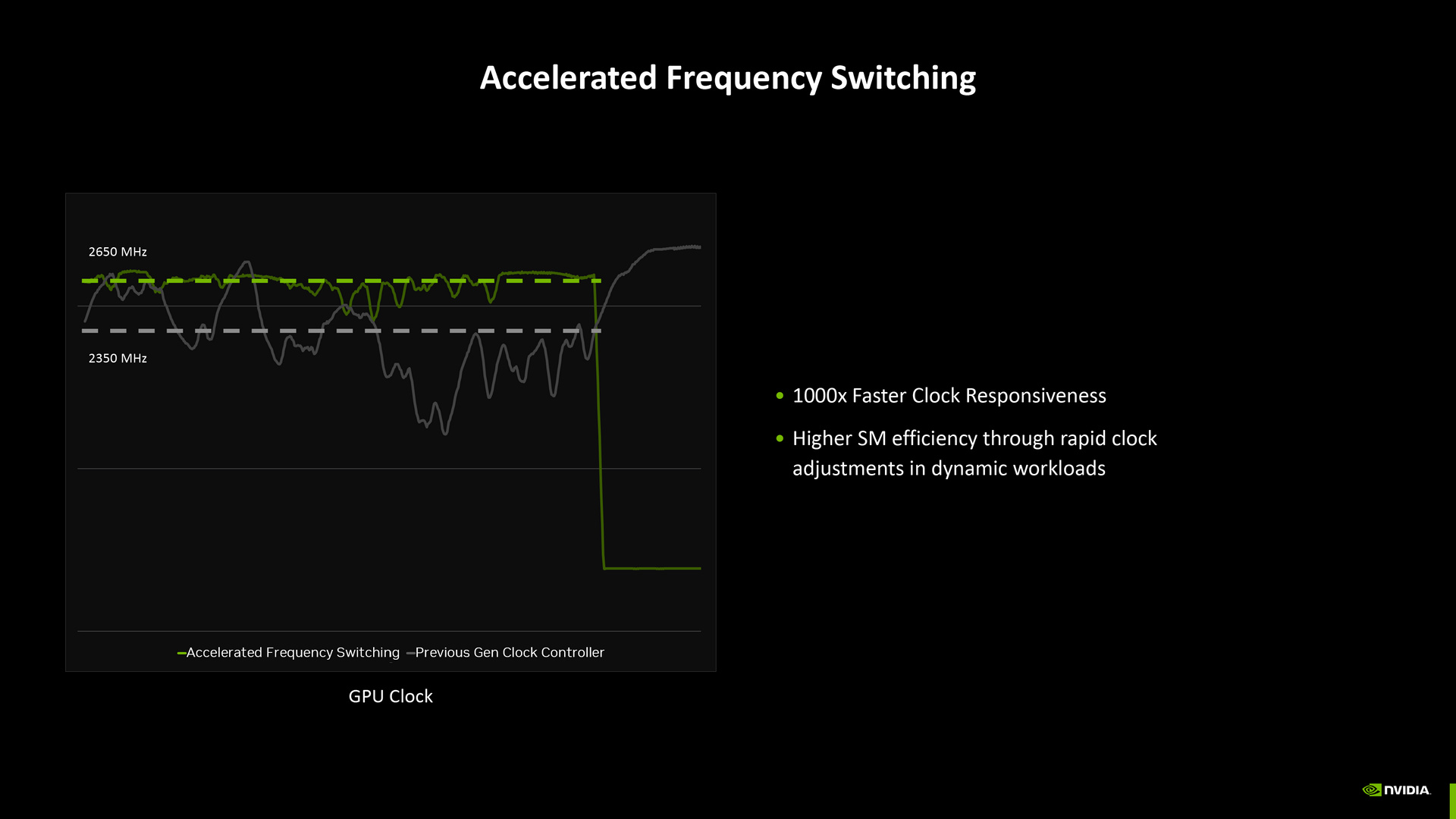
Blackwell 架構擁有更先進的節能設計,相較於 Ada 架構,Blackwell 由於效能更好,可更早完成工作負載並進入低功耗狀態,且透過新式的時脈、供電控制,讓低功耗狀態的效率更好,且進入深層休眠的延遲更少,總合起來 Blackwell 架構進入節能狀態的區間可較 Ada 架構節省達 50% 功耗。
Blackwell 架構也擁有更快速的時脈調控機制,可依工作附載需求動態調整著色器時脈,當然也就更有效率的運用能源。
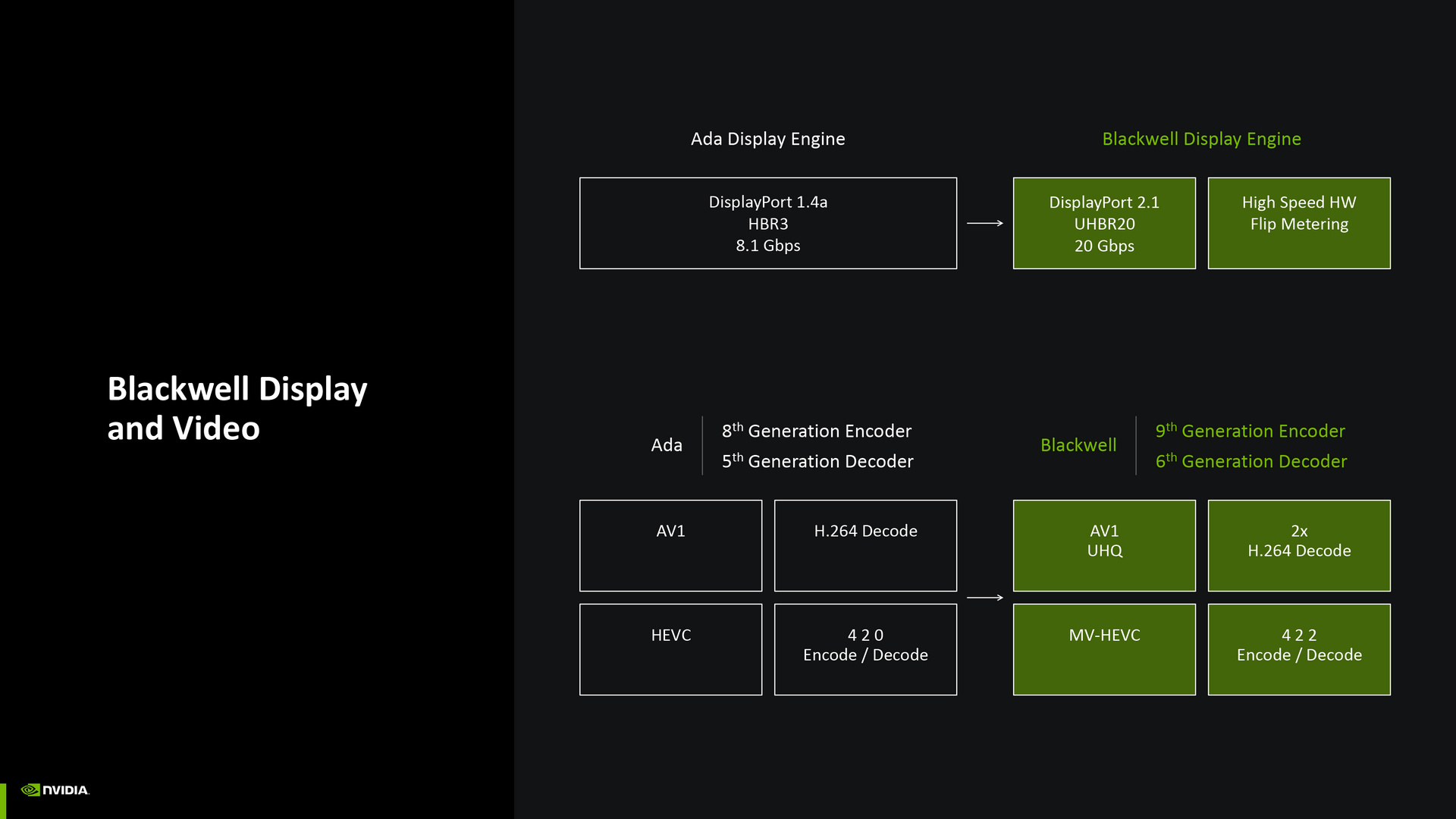
顯示引擎與視訊編碼核心也有大幅更新。首先,Blackwell 終於支援 DisplayPort 2.1 UHBR 20,視訊輸出頻寬可達 20 Gbps,同時導入高速硬體 Flip Metering,讓畫格輸出更穩定。
Blackwell 的第 9 代編碼器和第 6 代解碼器則帶來 AV1 UHQ(超高畫質 AV1)與 MV-HEVC(多視角 HEVC)編解碼,H.264 解碼能力擴增至 2 倍,以及 YUV422 的編解碼。
更多 GeForce RTX 50 系列 GPU 相關資訊,敬請鎖定本站的追蹤報導。
延伸閱讀:
:quality(60):no_upscale()/https%3A%2F%2Fimg.4gamers.com.tw%2Fckfinder%2Ffiles%2FElvis%2FNews%2F2025-01%2FNVIDIA%2Fblackwell-die-shot.jpg)
:quality(60):no_upscale()/https%3A%2F%2Fimg.4gamers.com.tw%2Fckfinder%2Ffiles%2FElvis%2FNews%2F2025-01%2FNVIDIA%2FBlackwell-Architecture-01.jpg)
:quality(60):no_upscale()/https%3A%2F%2Fimg.4gamers.com.tw%2Fckfinder%2Ffiles%2FElvis%2FNews%2F2025-01%2FNVIDIA%2FBlackwell-Architecture-02.jpg)
:quality(60):no_upscale()/https%3A%2F%2Fimg.4gamers.com.tw%2Fckfinder%2Ffiles%2FElvis%2FNews%2F2025-01%2FNVIDIA%2FBlackwell-Architecture-06.jpg)
:quality(60):no_upscale()/https%3A%2F%2Fimg.4gamers.com.tw%2Fckfinder%2Ffiles%2FElvis%2FNews%2F2025-01%2FNVIDIA%2FBlackwell-Architecture-04.jpg)
:quality(60):no_upscale()/https%3A%2F%2Fimg.4gamers.com.tw%2Fckfinder%2Ffiles%2FElvis%2FNews%2F2025-01%2FNVIDIA%2FBlackwell-Architecture-05.jpg)
:quality(60):no_upscale()/https%3A%2F%2Fimg.4gamers.com.tw%2Fckfinder%2Ffiles%2FElvis%2FNews%2F2025-01%2FNVIDIA%2FBlackwell-Architecture-07.jpg)
:quality(60):no_upscale()/https%3A%2F%2Fimg.4gamers.com.tw%2Fckfinder%2Ffiles%2FElvis%2FNews%2F2025-01%2FNVIDIA%2FBlackwell-Architecture-08.jpg)
:quality(60):no_upscale()/https%3A%2F%2Fimg.4gamers.com.tw%2Fckfinder%2Ffiles%2FElvis%2FNews%2F2025-01%2FNVIDIA%2FBlackwell-Architecture-03.jpg)
:quality(60):no_upscale()/https%3A%2F%2Fimg.4gamers.com.tw%2Fckfinder%2Ffiles%2FElvis%2FNews%2F2025-01%2FNVIDIA%2FBlackwell-Architecture-10.jpg)
:quality(60):no_upscale()/https%3A%2F%2Fimg.4gamers.com.tw%2Fckfinder%2Ffiles%2FElvis%2FNews%2F2025-01%2FNVIDIA%2FBlackwell-Architecture-11.jpg)
:quality(60):no_upscale()/https%3A%2F%2Fimg.4gamers.com.tw%2Fckfinder%2Ffiles%2FElvis%2FNews%2F2025-01%2FNVIDIA%2FBlackwell-Architecture-12.jpg)
:quality(60):no_upscale()/https%3A%2F%2Fimg.4gamers.com.tw%2Fckfinder%2Ffiles%2FElvis%2FNews%2F2025-01%2FNVIDIA%2FBlackwell-Architecture-13.jpg)